一、预测模型的基石:多源异构数据融合
精准预测的起点是高质量、多维度的数据。江南体育专业版的数据生态系统涵盖了以下核心层面:
核心数据维度
- 历史赛事数据:超过20年的全球主流联赛完整历史数据,包括比分、事件(进球、助攻、红黄牌)、球员出场时间等。
- 实时表现数据:通过计算机视觉与传感器技术采集的实时比赛数据,如球员跑动距离、速度、传球路线、射门角度等。
- 球队与球员状态数据:整合伤病报告、体能监测数据、近期训练负荷、球员心理状态评估(通过社交媒体情绪分析)。
- 环境与情境数据:比赛场地条件(草皮、天气)、主客场因素、旅行疲劳度、赛程密集度等。
- 市场与舆论数据:博彩市场赔率变化、新闻舆情热度、专家预测共识等,用于捕捉市场隐含信息和公众预期。
这些数据经过清洗、标准化和关联后,被统一存储在高性能数据仓库中,为后续的模型训练提供燃料。
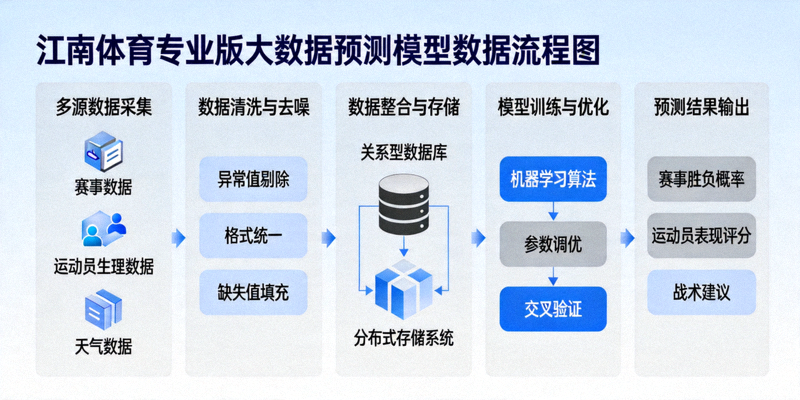
图1:江南体育专业版预测模型的数据整合与处理流程示意图
二、核心算法揭秘:集成机器学习模型
江南体育专业版并未依赖单一算法,而是采用了一套集成学习(Ensemble Learning)框架,结合多种模型的优势,以提升预测的鲁棒性和准确性。
特征工程与变量筛选
从原始数据中构建出数百个有预测价值的特征(Feature)。例如,将“过去5场比赛的平均控球率”与“对手过去5场比赛被射门次数”组合,生成“预期控球优势”特征。利用递归特征消除(RFE)和基于模型的重要性排序,筛选出对结果影响最显著的约80个核心变量。
基模型训练
并行训练多个不同类型的基模型(Base Model):
- 梯度提升决策树(如XGBoost, LightGBM):擅长处理结构化数据,捕捉复杂的非线性关系。
- 随机森林(Random Forest):提供稳定的预测和良好的特征重要性解释。
- 深度学习神经网络:特别用于处理序列数据(如球队近期状态序列)和图像数据(如比赛热力图)。
- 逻辑回归与泊松回归:作为基准模型,提供可解释的概率输出,尤其适用于预测进球数。
模型集成与元学习
使用堆叠集成(Stacking)或加权平均方法,将上述基模型的预测结果作为新的特征,输入到一个“元模型”(Meta-Model,通常为简单的线性模型或另一层GBDT)中进行最终训练。元模型学习如何最优地组合各基模型的预测,从而获得比任何单一模型都更优的泛化性能。
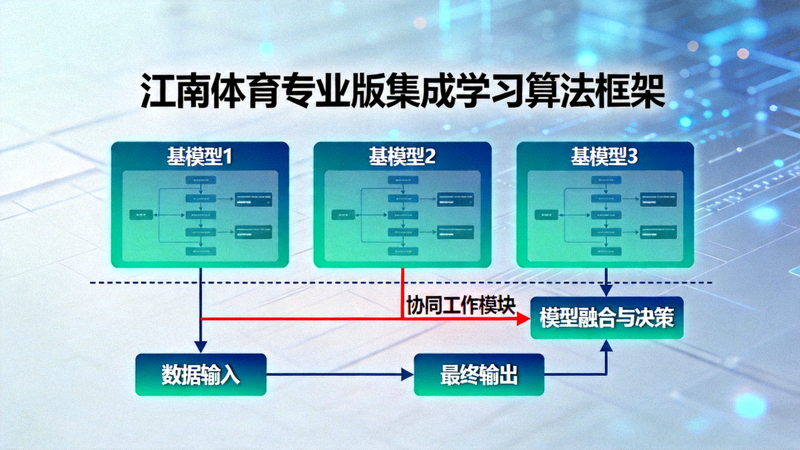
图2:集成学习模型框架,结合多种算法优势进行最终预测
三、预测输出与不确定性量化
模型输出的不仅仅是简单的“胜平负”预测,而是一个完整的概率分布,并附带对预测可信度的评估。
| 输出类型 | 描述 | 应用场景 |
|---|---|---|
| 胜平负概率 | 主队胜、平局、客队胜的精确概率值(如:胜 48.5%,平 28.2%,负 23.3%)。 | 赛事结果基本面分析,趋势判断。 |
| 精确比分概率 | 基于泊松分布和团队攻防能力修正,给出各种比分(如1-0,2-1)出现的可能性。 | 高风险高回报的精准预测场景。 |
| 预期进球(xG)值 | 预测双方在本场比赛中可能获得的进球机会质量总值。 | 评估球队进攻效率与防守质量,即使比分未能反映真实场面。 |
| 预测区间与置信度 | 使用分位数回归或贝叶斯方法,给出预测值的可能范围(如:主队进球数 1.2 - 2.4,置信度90%)。 | 风险管理,理解预测的不确定性。 |
四、持续进化:模型迭代与反馈循环
预测系统并非一成不变。江南体育专业版建立了完整的模型监控与迭代管道:
- 实时监控:持续追踪模型在最新比赛中的预测表现,一旦预测准确率出现统计显著下滑,立即触发警报。
- 在线学习:部分模型采用在线学习机制,能够用最新产生的比赛数据微调参数,适应联赛战术风格或规则的变化。
- A/B测试:将新开发的算法版本与当前生产版本进行对比测试,只有稳定表现更优的新模型才会被部署。
- 专家反馈融入:将资深分析师对特定情境(如关键球员突然伤退、球队内部矛盾)的定性判断,作为特征或后处理规则融入系统,弥补纯数据模型的盲区。
通过上述机制,预测系统能够像一支优秀的球队一样,不断学习、适应和进化。
结语:数据驱动决策的新范式
江南体育专业版通过大数据预测赛事结果,其本质是将体育竞技中大量模糊的、经验性的认知,转化为可量化、可分析、可迭代的数据科学问题。这并非要取代教练的临场指挥或球迷的热情,而是提供一种强大的辅助决策工具和深度理解比赛的新视角。
未来,随着传感器技术、自然语言处理(分析教练采访、战术报告)和更强大算力的发展,预测模型将变得更加精细和前瞻。江南体育专业版将持续投入研发,推动体育数据分析领域的边界,让数据真正赋能于每一个热爱体育的人。